
 The growth of generative AI and Large Language Models has restarted a fundamental question about the value of a millisecond of latency. When I was at Telefonica, and later, consulting at Bell Canada, one of the projects I was looking after was the development, business case, deployment, use cases and operation of Edge Computing infrastructure in a telecom network.
The growth of generative AI and Large Language Models has restarted a fundamental question about the value of a millisecond of latency. When I was at Telefonica, and later, consulting at Bell Canada, one of the projects I was looking after was the development, business case, deployment, use cases and operation of Edge Computing infrastructure in a telecom network.
Since I have been developing and deploying Edge Computing platforms since 2016, I have had a head start in figuring out the fundamental questions surrounding the technlogy, the business case and the commercial strategy.
Where is the edge?

The first question one has to tackle is where is the edge. It is an interesting question because it depends on your perspective. the edge is a different location if you are an hyperscaler, a telco network operator or a developer. It can also vary over time and geography. In any case, the edge is a place where one can position compute closer than the current Public or Private Cloud Infrastructure in order to derive additional benefits. It can vary from a regional, to a metro to a mini data center, all the way to on premise or on device cloud compute capability. Each has its distinct cost, limitation and benefit.
What are the benefits of Edge Computing?
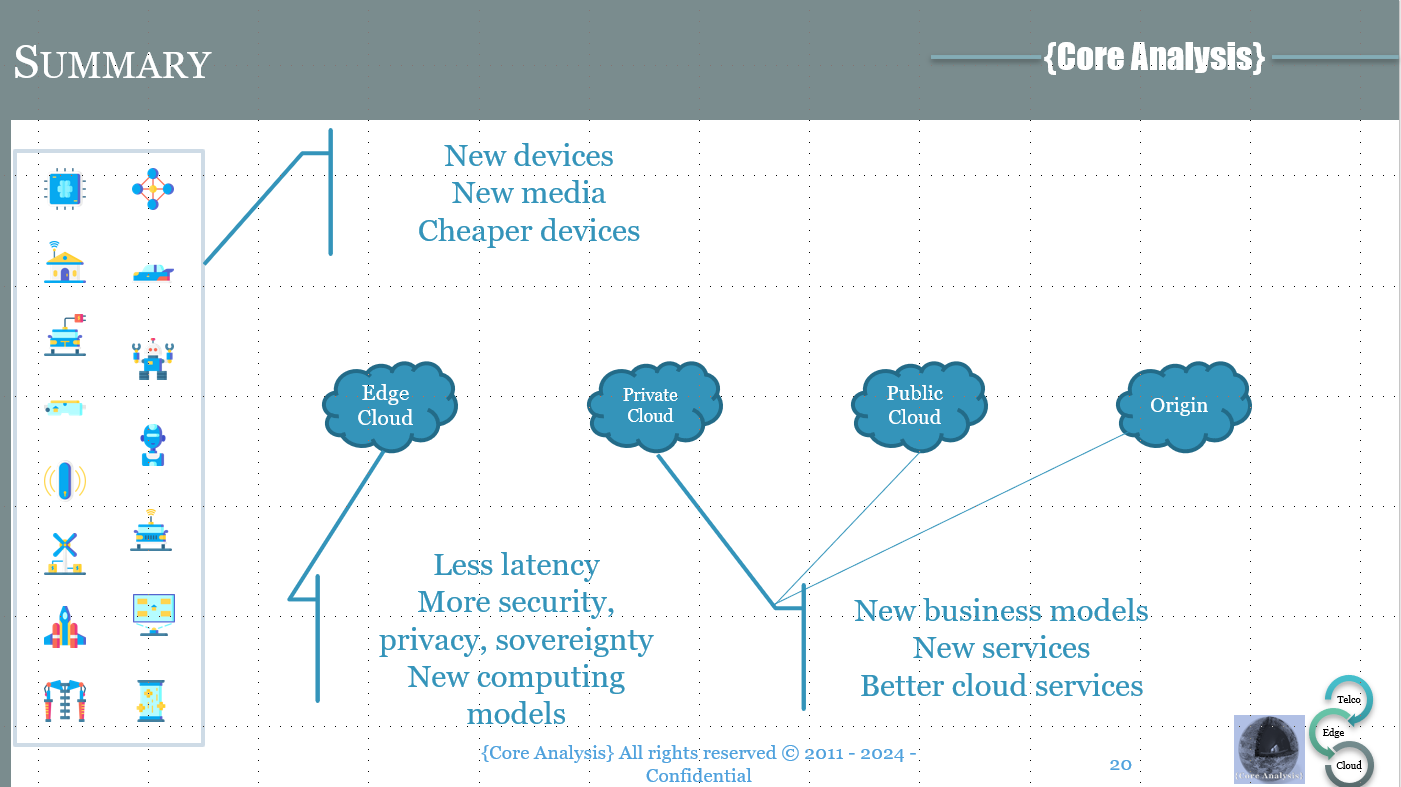
The second question, or maybe the first one, from a pragmatic and commercial standpoint is why do we need edge computing? What are the benefits?
While these will vary depending on the consumer of the compute capability, and where the compute function is located, we can derive general benefits that will be indexed to the location. Among these, we can list data sovereignty, increased privacy and security and reduced latency, enabling cheaper (dumber) devices, the creation of new media types and new models and services.
What are the use cases of Edge Computing?
I have deployed and researched over 50 use cases of edge computing, from the banal storage, caching and streaming at the edge to the sophisticated TV production or the specialized Open RAN or telco User Plane Function or machine vision use cases for industrial and agriculture application.
What is the value of 1ms?

But obviously, there is a cost. The latency will be proportional to the distance, so the fundamental question becomes what is the optimal placement of a compute resource, for which use case? Computing is a continuum and some applications and workload are not latency or privacy or sovereignty sensitive and can run on an indiscriminate public cloud, while others necessitate the compute to be in the same country, region or city. Others even require a closer proximity. The difference is staggering in terms of investments between a handful of centralized data centers and several hundreds / thousands? of micro data center.
What about AI and LLM?
Until now, these questions where somewhat theoretical and were answered organically by hyperscalers and operators based on their respective view of the market evolution. Generative AI and its extraordinary appetite for compute is rapidly changing this market space. Not only Gen AI accounts for a sizable and growing portion of all cloud compute capacity, the question of latency now is getting to the fore. Gen AI relies on Large Language Models that require large amount of storage and compute, to be able to to be trained to recognize patterns. The larger the LLM, the more compute capacity, the better the pattern recognition. Pattern recognition leads to generation of similar results based on incomplete prompts / question / data set, that is Gen AI. Where does latency come in? Part of the compute to generate a response to a question is in the inference business. While the data set resides in a large compute data center in a centralized cloud, inference is closer to the user, at the edge, where it parses the request and attempts to feed the trained model with unlabeled input to receive a prediction of the answer based on the trained model. The faster the inference is, the more responses the model can provide, which means that low latency, is a competitive advantage for a gen AI service.
As we have seen there is a relatively small number of options to reduce latency and they all involve large investment. The question then becomes: what s the value of a millisecond? Is 100 or 10 sufficient? When it comes to high frequency trading, 1ms is extremely valuable (billions of dollars). When it comes to online gaming, low latency is not as valuable as controlled and uniform latency across the players. When it comes to video streaming, latency is generally not an issue, but when it comes to machine vision for sorting fruits on a mechanical conveyor belt running at 10km/h, it is very important.
If you would like to know more, please get in touch.
No comments:
Post a Comment